Demo projects
Some of the more interesting projects I've done as a demo in 2023-2025
Churn prediction model CLI
A demo I made in 2025, I was curious to learn the basics of training a machine learning model.
https://github.com/NiceSlice/churn_prevention_model
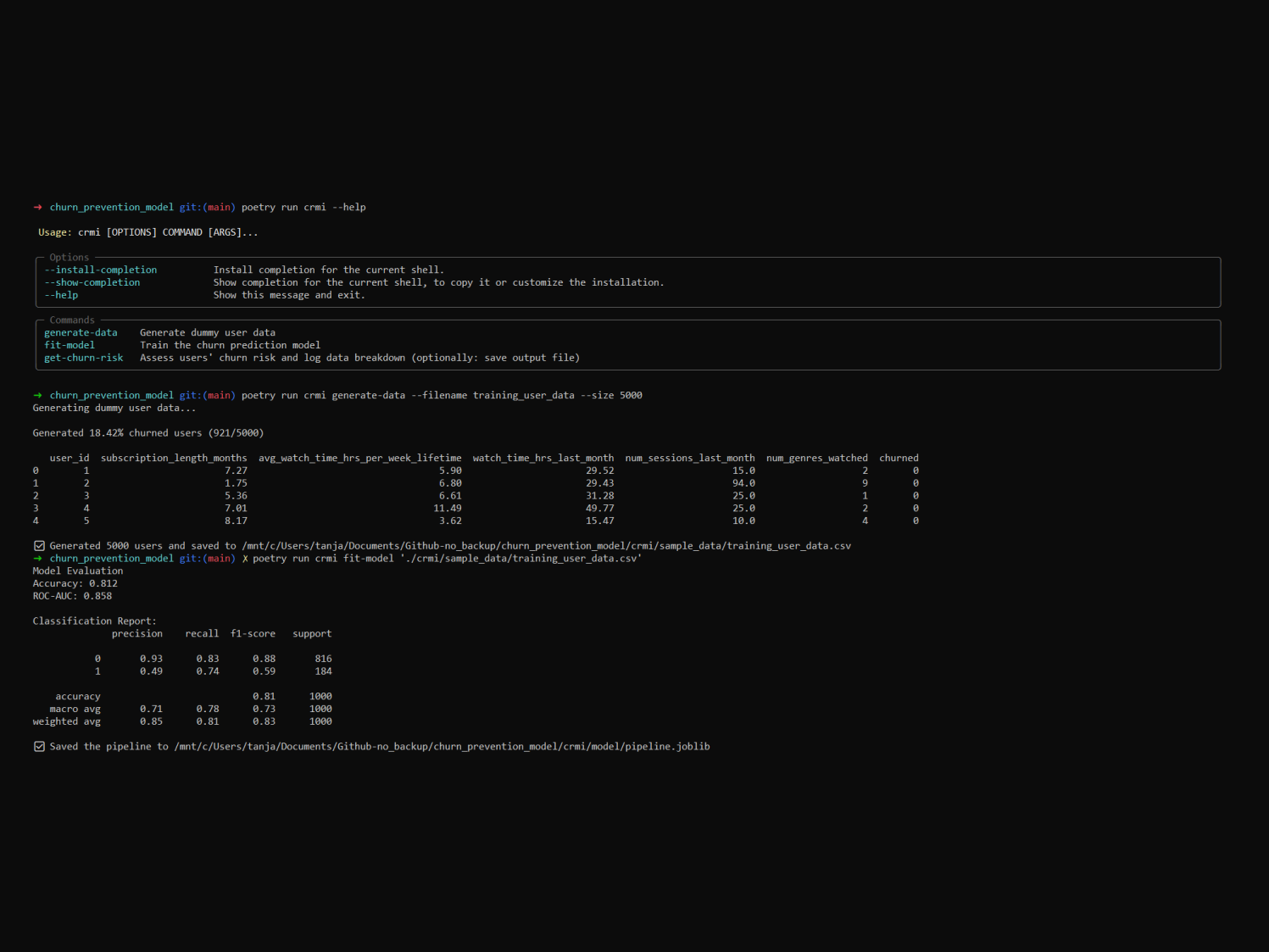
I used Typer to create a simple CLI tool for the demo – CRMI (customer relationship management interface).
For the predictive ML model I used logistic regression and a standard scaler from scikit-learn. I chose logistic regression because it’s simple, interpretable and fast to train, it serves as a good baseline.
First I wrote dummy data generation script, trying to model the dataset values in a plausible way with different distributions using numpy and pandas.
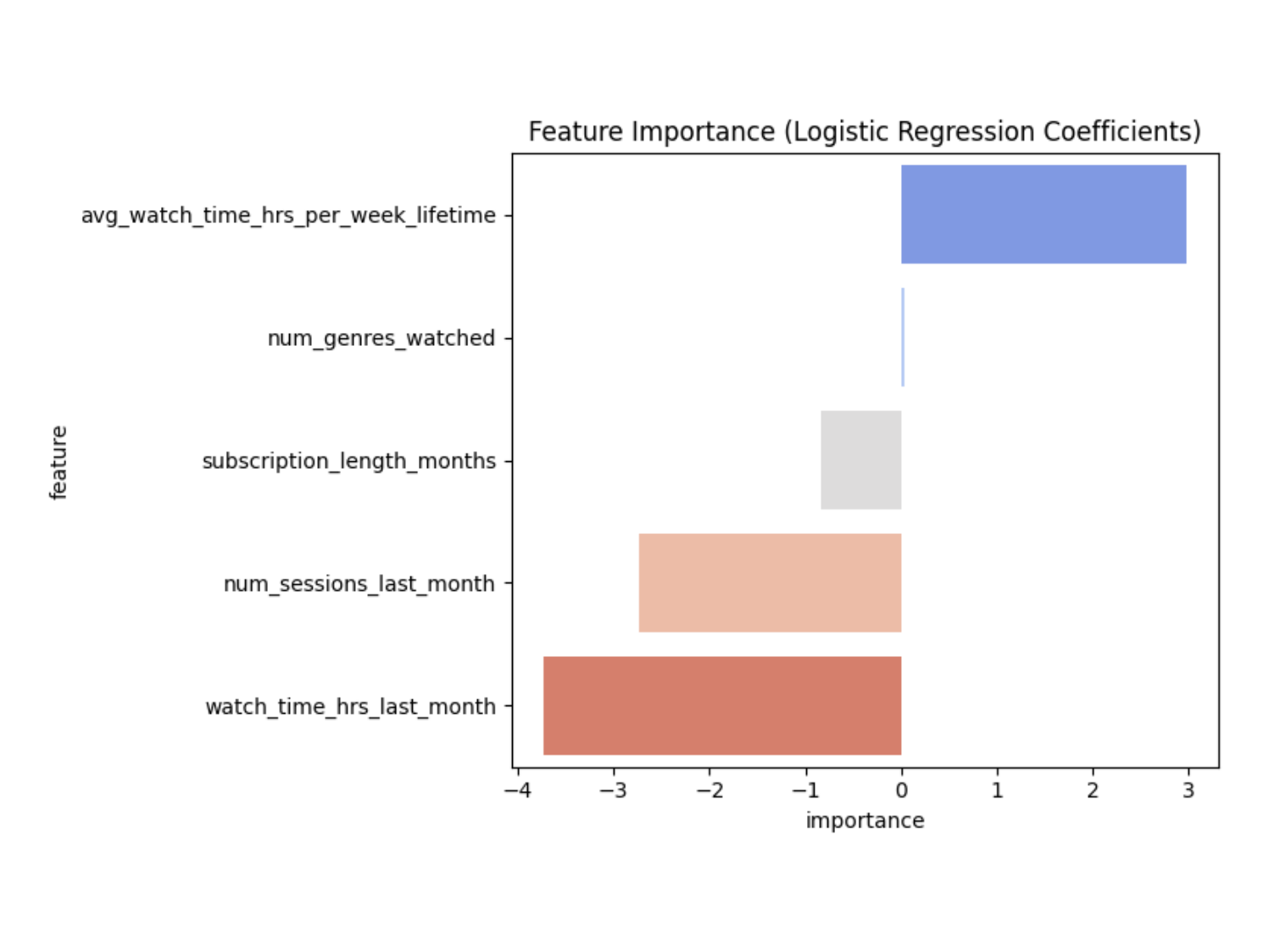
When calculating churn probability I gave watch time the highest coefficients and included a variable that had no effect at all - number of genres watched.
The model trained on the dummy data correctly identified feature importance, showing watch time as the biggest predictor for churn and number of genres watched as having little to no effect, consistent with the coefficients I assigned.
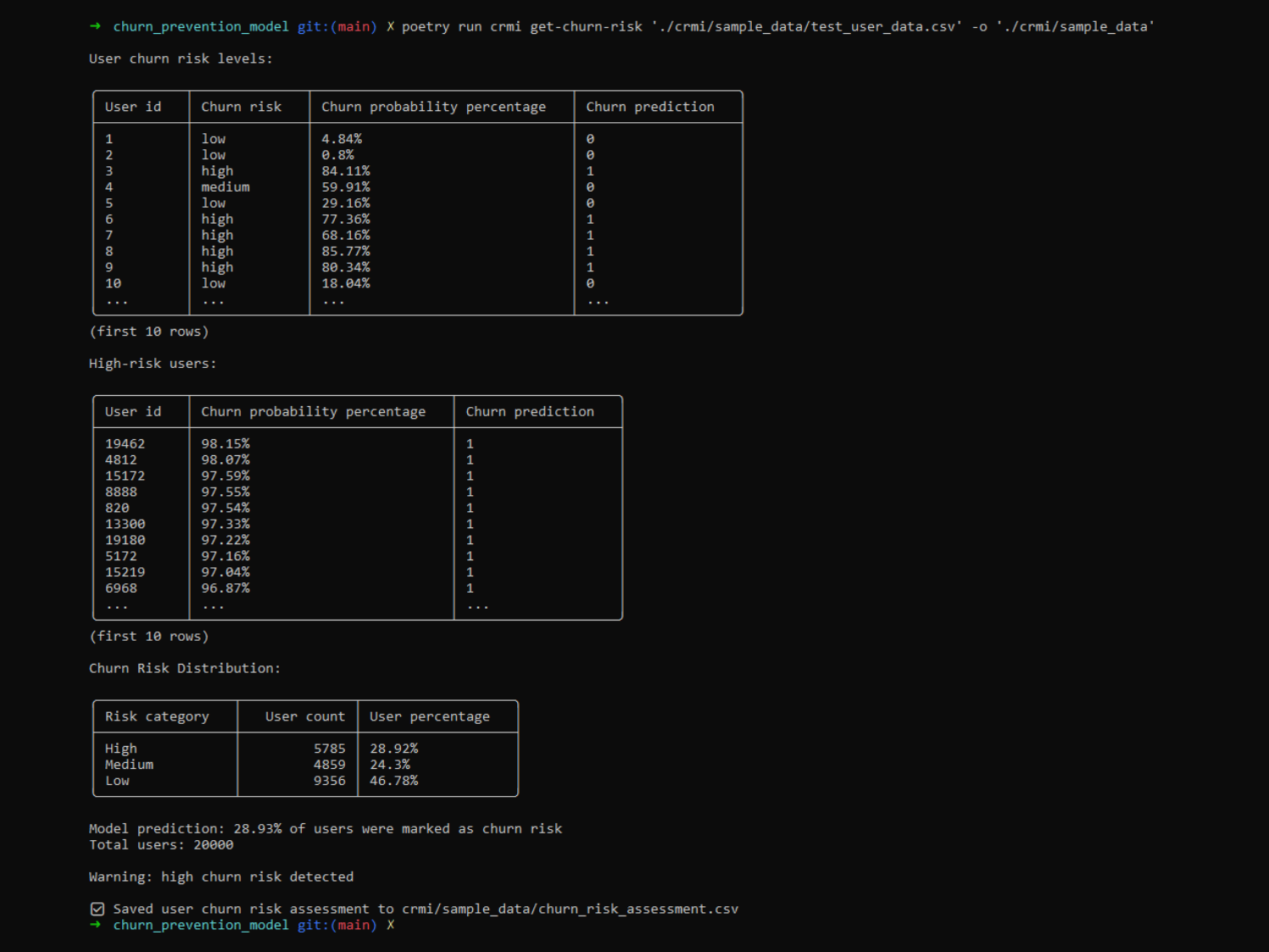
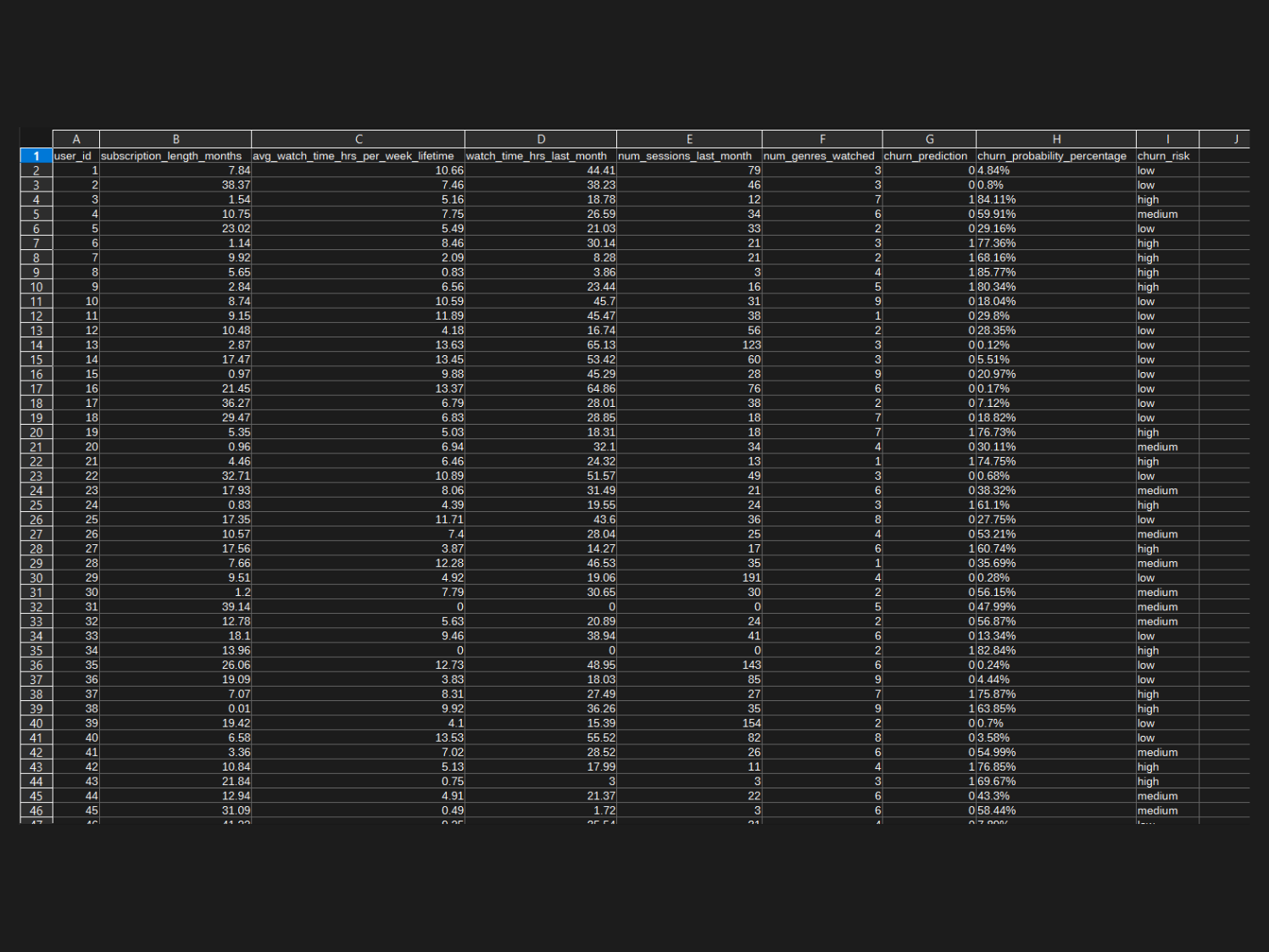
I then used the model on a dataset of ‘active users’ to predict their churn risk, and log the prediction breakdown. This includes marking users as low / medium / high churn risk and logging a warning if the percentage of high risk users is over a predefined threshold.
Overall I loved getting familiar with the basic concepts and working with machine learning, I hope to get a chance to do so again in the future!Subtitle translation CLI
AI subtitle translations demo made in 2025, a CLI tool that translates .srt files using LLM for a more nuanced result.
https://github.com/NiceSlice/AI_subtitle_translation
My focus was on how to set up the project rather than the choice of LLM as it seems easy enough to check their benchmarks and switch out for a different model at any time.
I used langchain as a thin wrapper around LLM calls. There’s a few other libraries included in the project, namely: typer for building the CLI, pysrt for parsing .srt subtitle files, langdetect for language detection.
A key part of the project was to think about how to account for LLM’s faulty responses:
-
Instead of putting a chopped up .srt file into the prompt and requesting another back I only put in the subtitle text to ensure the timestamps and the formatting of the .srt file can’t change
-
The prompt requires specific formatting, then it’s ran through checks to validate it and catch inconsistencies. These checks should be further extended to make it more robust - examples of additional checks could be to see if any formatting or special characters were added in the translation that don’t appear in the original, detect the output language to see if it matches with the target language, and check whether the word count of the translated subtitle line roughly matches the word count of the original
-
In case the response is detected as faulty (even after retries) the fallback is to feed the subtitles to the LLM line-by-line. In a production environment it should be considered whether a more robust system and other fallbacks are needed, depending on how the program is used
-
It would be good to log all the responses LLM gave, which ones didn’t pass, why, etc.
Column calculations
A small demo I’ve done in 2023 as a part of an interview process – I’m keeping the source code private for that reason.
The idea was to take a React app with Blueprint.js table and implement an excel-like formula feature that allows the user to reference existing columns in calculations in new columns, e.g. column C can equal column A + column B. This includes a special function for calculation of a rate of change of a column.